
Par James the photographer — https://www.flickr.com/photos/22453761@N00/592436598/, CC BY 2.0, Lien

Par Paweł Grochowalski — Travail personnel, CC BY-SA 3.0, Lien
En 1997 IBM grace à son super ordinateur Deep Blue bat le champion d'échec de l'époque Garry Kasparov.
Par James the photographer — https://www.flickr.com/photos/22453761@N00/592436598/, CC BY 2.0, Lien
Par Paweł Grochowalski — Travail personnel, CC BY-SA 3.0, Lien
L'algorithme de Deep blue était basé sur la force brute, l'ordinateur examine tous les prochains coups successifs possibles et choisi la meilleure possibilité pour lui.
Un problème est la complexité de l'algorithme, la force brute est exponentielle par rapport au nombre de coups successifs (si on le programme pour un puissance 4 par exemple l'algorithme est en \(\Theta(7^n)\) et donc rapidement la puissance de l'ordinateur sera insuffisante et il est donc impossible d'aller jusqu’à la fin du jeu et doit doit s’arrêter à 7-8 coups à l'avance si on veut un temps de calcul raisonnable.
Pour cette méthode il faut aussi une fonction d'évaluation d'une position, qui doit être faite par un expert du jeu. Cette fonction est nécessaire pour savoir justement quelle position est la meilleure.
A cette époque un jeu résistait à la force brute : le go, et à l'époque on pensait que jamais un ordinateur battrait (un bon) joueur humain.
En 2016, le programme alphago (appartenant à Google) bat Lee Sedol un des meilleurs joueurs de go au monde:
![]()
Par Google DeepMind — Google DeepMind AlphaGo Logo, Domaine public, Lien

Par LG Electronics — https://www.flickr.com/photos/lge/26980691250/in/dateposted/, CC BY 2.0, Lien
Le programme ne se repose plus uniquement sur la force brute, il utilise aussi des techniques d'apprentissages.
L'algorithme des plus plus proches voisins est un algorithme de prédiction, par exemple :
Le principe de l'algorithme est assez simple et on va le décrire dans le cas de points :
L'iris est une fleur qui a au moins trois variétés :

Par Gouvernement du Québec — http://www.drapeau.gouv.qc.ca/emblemes/iris/galerie-images.html, Copyrighted free use, Lien

By Eric Hunt - Own work, CC BY-SA 4.0, Link
On récupére 150 données sur la longueur et la largeur des pétales des fleurs. Sur la représentation graphique de ses données on constate trois groupes distincts. l'algorithme knn essaye de remplacer l'oeil humain pour savoir dans quel groupe on se trouve.
Généralement on divise la base des données en deux, une partie des données va servir à "apprendre" et l'autre à tester pour savoir si notre distance ou si le choix de k est pertinant.
Dans un premier temps, entrez différents exemples de trois symboles. Ensuite entrer une des trois formes et lancez le bouton correspondance, il lancera l'algorithme des k plus proches voisins pour essayer de trouver quel symbole vous avez essayé de dessiner.
| Symbole 1 | ||||||||
|---|---|---|---|---|---|---|---|---|
| Symbole 2 | ||||||||
| Symbole 3 |
La distance utilisée ici effectue la racine de la somme des différences au carré pour chaque pixel de l'image 1 et du même pixel de l'image 2. Pour simplifier, si l'image est constituée de 4 pixels ou noirs (codé à 1) ou blancs (codé à 0) alors la distance entre les deux images ci dessous est :
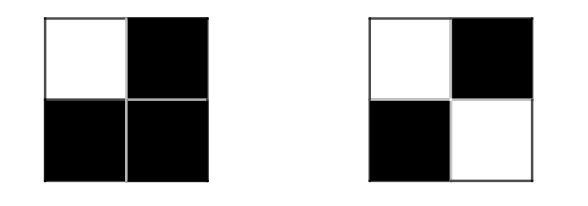
est égale à \(\sqrt{(0-0)²+(1-1)²+(1-1)²+(0-1)²} = 1\)
Le deep learning utilise une technique très différente d'apprentissage basée sur un réseau de neurones, donnons le principe très simplifié pour l'ewemple suivant, en entrée et en sortie nous avons deux bits, nous souhaitons que le réseau apprenne la fonction suivante :
| E1 | E2 | S1 | S2 |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 |
Partons d'un réseau de neurone suivant (les nombres sont générerer aléatoirement au début):

Il faut maintenant faire "apprendre", l'opération consiste à donner des entrées, à voir les sorties obtenus par le réseau et à les comparer avec les vraies sorties.
Si on donne l'entrée E1 = 1 et E2 = 0 alors on obtient :

Là on calcule les erreurs en comparant avec les bonnes réponses et on fait deux choses :
on répercute les erreurs de facon proportionnelle, par exemple neurone S1 dit être à 1 et pas à 0.19 on a donc une erreur de -0.81, cette erreur vient au 3/4 (0.3/(0.3+0.1)) de N1 et au 1/4 de N2 donc l'erreur sur S1 va donner une erreur de -0.60075 sur N1 et de -0.2025 sur N2 on ajoute ensuite l'erreur qui vient de S2.

On modifie les coefficients entre les neurones en utilisant une formule mathématique qui généralise la notion dérivation vu en cours de mathématiques (on parle de gradient). Cette opération est compliquée car il ne faut pas modifier trop rapidement les coefficients. Les modifications ci dessous sont totalement fictive mais donne l'idée.

Pour aboutir à un réseau performant il faut beaucoup l’entraîner et cela demande énormément de temps de calcul, heureusement cette opération est parallélisable dans l'ordinateur. Dans l'exemple ci dessous qui correspond aux problèmes des Iris j'utilise un réseau de 6 × 3 neurones (comment choisir la bonne taille ? je ne sais pas).
Le problème vient de l’entraînement, mon jeu de données sur les fleurs est bien trop petits (si bien que je triche en ré entraînant avec les mêmes valeurs, ce qui fausse la chose).
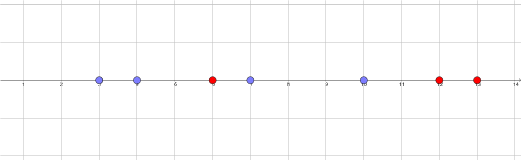
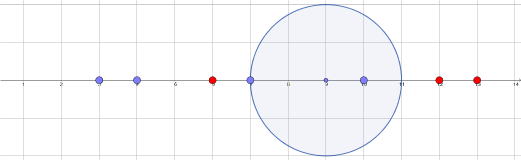
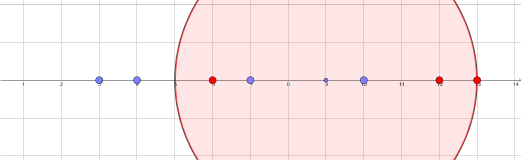
Pour avoir un exemple plus parlant je divise le plan repéré euclidien en trois parties, la première des points M tels que OM < 1, le deuxième des OM < 2 et l reste. Comme ça je peux entraîner facilement :
Essayer de dessiner des zones de couleurs.
Definir le nombre de neurones par couche.
couche 1 :
couche 2 :
couche 3 :
couche 4 :
couche 5 :

{kind=link}
{kind=link}