.svg)

Par en:MySQL.svg — http://www.mysql.com + Convertion de EPS avec Scribus et Ghostscript., marque déposée, Lien
La gestion des données est d'une importance capitale aujourd'hui et ceci dans de nombreux domaines (financiers, commerciaux, recherche, administratifs, web...), voici une série de problématique liée au sujet :
l'an dernier nous avons abordé le sujet à travers les fichiers CSV (si on veut à travers une page d'un tableur), cette façon de faire ne permet pas de gérer efficacement les problématiques précédentes.
Pour gérer les bases de données les informaticiens utilisent des logiciels dédiés à la chose, les systèmes de gestion de base de donnés (SGBD) qui vont s'occuper des problématiques précédente à notre place.
Une autre particularité des SGBD : si l'an dernier nous étions obligés à chaque fois de faire un petit programme pour répondre aux questions (trouver la ligne correspondant à "Wissembourg" par exemple, avec les SGBD il suffit de demander et le logiciel s'occupera de trouver la réponse. Néanmoins la demande doit être très précise et se fait à l'aide d'un langage particulier à savoir et qui dépend la façon de stocker les données du SGBD. Dans le modèle relationnel le langage utilisé est le SQL.
Malgré la grande importance des base de données sur le net et en entreprise, le grand public ne connaît pas les systèmes de gestion de base de donnés car il n'en a pas directement usage (par contre il les utilise sans s'en rendre compte, sur le web par exemple, massivement mais de façon invisible).
Parmi les SGBD citons :
Par en:MySQL.svg — http://www.mysql.com + Convertion de EPS avec Scribus et Ghostscript., marque déposée, Lien
Tous les SGBD font globalement la même chose mais avec plus ou moins d'efficacité (vitesse et mémoire). Ils ont chacun des petites variantes dans la syntaxe du langage SQL (pas grand chose cependant).
Dans le cadre du cours, nous utiliserons SQlite :

Par Part of the SQLite documentation, which has been released by author D. Richard Hipp to the public domain. SVG conversion by Mike Toews. — SVG created from sqlite370.eps, distributed with version 3.7.2 documentation, Domaine public, Lien
Généralement les SGBD sont des serveurs, par exemple si vous effectuez une requête sur un magasin en ligne :
Ca semble compliqué mais les avantages de ce fonctionnement sont nombreux, notamment le SGBD peut s'occuper de toutes les demandes et notamment de la concurrence des demandes.
SQLite fonctionne différemment, c'est un programme qu'on lance mais qui n'est pas un serveur, ça signifie que si la base de données est ouverte simultanément dans deux programmes différents, les modifications sont impossibles. SQLite est très adapté si il n'y a pas concurrence, les applications de vos mobiles qui sont indépendantes les unes des autres l'utilisent massivement par exemple.
Il existe de nombreux façon de stocker des données, certaines sont plus adaptées à certains problèmes que d'autres, néanmoins un modèle domine le marché actuellement : le modèle relationnel (Tous les SGBD evoqués précédement l'utilisent).
En 1970, Edgar Franck Cood (1923-2003) invente le modèle relationnel, dix ans plus tard la société Oracle (Une des plus grandes entreprises en informatique inconnue pourtant du grand public) implémente ses idées dans un système de base de données qui connaîtra le succès (et qui se nomme simplement Oracle Database), le SGBD Oracle est leadeur du marché des SGBD commerciaux.
Dans un modèle relationnel les données sont réparties entre différentes tables (aussi appelées relations et qui peut être comparé au contenu d'un fichier CSV), chaque table va représenter un élément précis et contient des colonnes (aussi appelées champs ou encore attributs) qui caractérisent l’élément et qui seront typés. Chaque entrée sera représentée par une ligne de la table.
Dans chaque table, un ou plusieurs attributs formeront une clef primaire, cette clef primaire va caractérisée de manière unique une ligne d'une table.
On veut pour toutes les communes, régions et département de France connaître la superficie, la population, le nom le numéro éventuellement attaché. De plus on veut savoir à quel département et à quelle région appartient une ville, a quelle région appartient un département.
Le problème ressemble (volontairement) à un exercice de l'an dernier avec cependant l'ajout du nom du département et de la région. Si on le traite dans un fichier CSV on va se retrouver avec de nombreuses répétitions (Il y a aura plein de Grand Est et de Bas Rhin par exemple), ses différentes répétitions vont alourdir le fichier et ralentir les recherche.
La bonne modélisation d'une base de données est un problème difficile et important pour les performances futur de la base, ce n'est pas une chose que l'on peut vous demander en terminale, néanmoins le problème est ici relativement simple pour pouvoir comprendre la modélisation et aborder les difficultés.
Déjà il faut éviter la redondance des données, cela à l'air simple mais cela ne l'est pas par exemple si on place la population d'un région dans les données on va avoir une redondance avec la population des villes : la population d'une région est la somme des populations des villes qui la composent. Pareil pour la superficie (je ne suis pas géographe, peut être que c'est faux et des territoires sont hors commune. Il faut conserver seulement les données que l'on ne peut pas retrouver (après en pratique on accepter certains doublons si cela fait gagner en performance).
Ensuite vient la répartition des données, ici elles sont attachées à trois "entités" différentes , la ville, le département et la région. Par exemple la superficie et la population sont rattachées à la ville.

Les trois tables sont reliées entre elles par appartenance à l'entité supérieure, 11 signifie qu'une ville appartient forcément à un et uniquement à 1 département. 1N signifie qu'un département à au minimum une commune et peut en avoir plus (N est une indéterminée).
Dans chaque table, if faut choisir un ou plusieurs attributs qui vont caractériser de manière unique une ligne de la table, par exemple le nom département peut être une clef primaire car il n'existe pas deux départements ayant le même nom, mais le nom de la ville ne peut pas être clef primaire car il y a de nombreuses communes qui ont le même nom.
Comme les SGBD crée généralement automatiquement un numéro pour désigner une ligne, on peut l'utiliser comme clef unique c'est les nombres appelés id_ville,id_region et id_departement, l'avantage est que l'on est certain de ne pas avoir de problèmes de répétition, l'inconvénient est que le nombre n'a pas de sens dans le contexte (il n'est pas certain que l'id du Bas Rhin soit 67 par exemple).

Pour éviter de faire des erreurs on peux fixer des contraintes aux attributs à la création de la table, on peut demander par exemple que le numéro de département soit unique (comme ça on ne pourra pas entrer deux fois 67, ou doubler les données).
On doit donner un type aux attributs, pour permettre au SGBD d'optimiser la mémoire et pour ajouter des contraintes on doit donner un type aux attributs, comme ça on ne risque pas de mettre "Wissembourg" dans l’attribut population. Avec Python le typage est dynamique mais ici on doit le donner explicitement au moment de la création (comme avec la langage C).
Nous nous attacherons plus tard à créer une petite base de donnés, les commandes suivantes sont indicatives.
Télécharger la base de données. Quand toutes les données sont entrées on obtient trois tables :

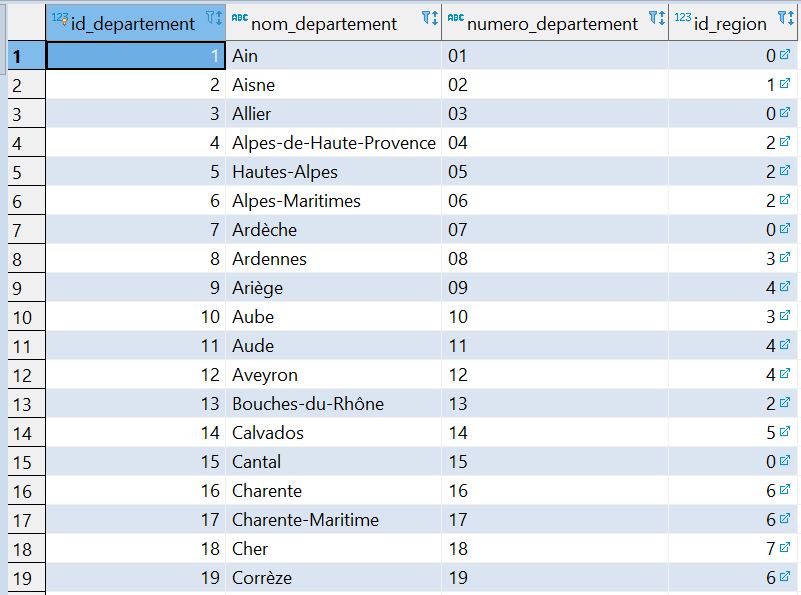
Il y a 101 lignes.
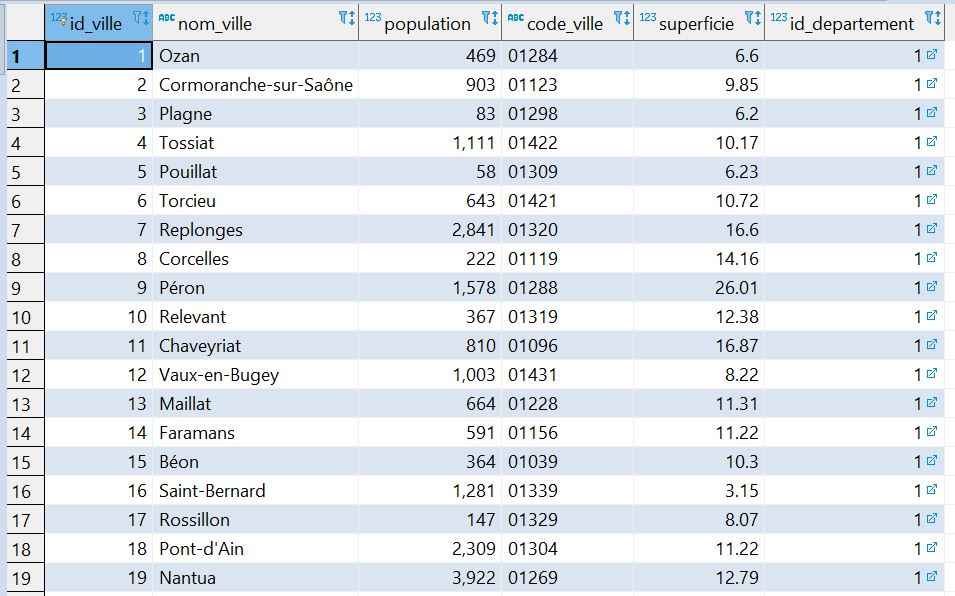
Il y a 36 699 lignes.
Comme vous voyez on ne voit pas la région d'une ville ou la superficie des régions. Pour le faire on va effectuer des requêtes.
{kind=link}